



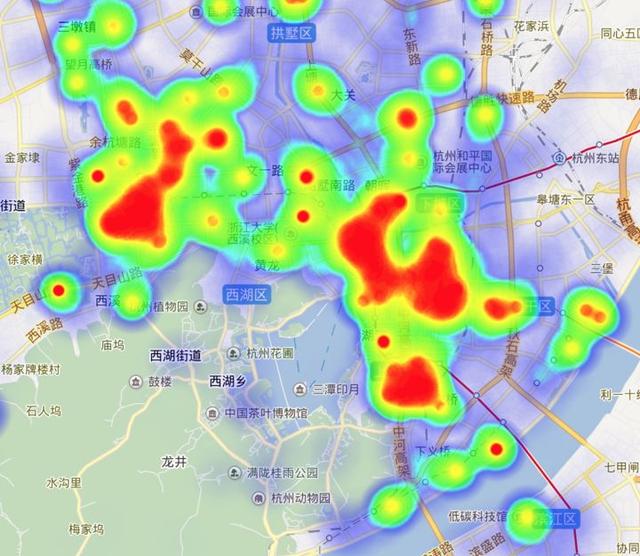
我们经常在百度地图上看到类似这种的热力图,那么这种热力图究竟是什么原理?我们如何应用它来分析实际问题呢?
1.热力图原理
热力图这个名字可能听起来很高大上,但是实际上它等同于我们常说的密度图。
看到上面的图片你可能 会想到我之前写的热点分析图,它和热力图经常被搞混。
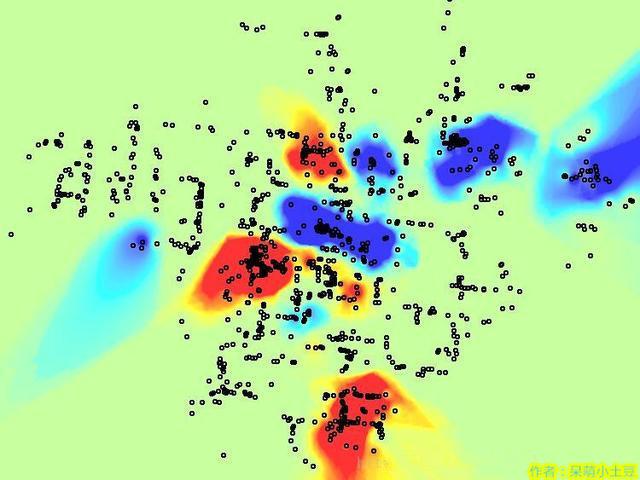
这两种图虽然都被用来显示地理数据活动发生的高密度或高聚集区域,但是完全不是一回事。
1.1 热力图和热点图的区别
他们直接分析的结果是不同
在Arcgis中,热点分析的结果和源图层是统一类型的,比如源图层是点图层,那么热点分析的结果也将是点。只不过每个点多了一个得分,这个得分以他们的Z值和P值决定。
而对一个点图层直接进行核密度分析,它的结果直接就会生成密度图。
他们的直接原理不同
我们看上面的热点图,上面有深蓝也有深红的区域,这些都是聚类区域,只不过一个表示高值聚类,一个表示低值聚类。而某些要素聚集的区域,高值低值都存在,则P值就会接近于1,而Z值也会小,最终不会表现为聚类区域。
而热力图,红色的区域表示分析要素的密度大,而蓝色区域表示分析点的密度小。只要点【360竞价开户】密集,就会形成聚类区域。在Arcgis我们要想生成这样的热力图就要用到核密度分析工具。
1.2核密度分析的原理
我们看到密度分析下有三个工具:

核密度和点密度的区别在哪呢?
我们先看看核密度分析的定义:
官方的解释是:使用核函数根据点或折线 (polyline) 要素计算每单位面积的量值以将各个点或折线 (polyline) 拟合为光滑锥状表面。
从以上的说明我们可以看到两个重要信息:
【百度推广开户】1:进行核密度分析的图层可以使点图层和线图层。
2:核密度分析最终生成的是光滑表面。
再来看点密度分析的定义:
根据落入每个单元周围邻域内的点要素计算每单位面积的量级。
线密度分析:
根据落入每个单元一定半径范围内的折线 (polyline) 要素计算每单位面积的量级。
发现,只有核密度分析强调了光滑二字。核密度分心中,落入搜索区的点具有不同的权重,靠近搜索中心的点或线会被赋予较大的权重,反之,权重较小,它的计算结果分布较平滑。
对于普通的点密度分析,你只需要指定一个范围,计算落入范围内点或县的密度即可。
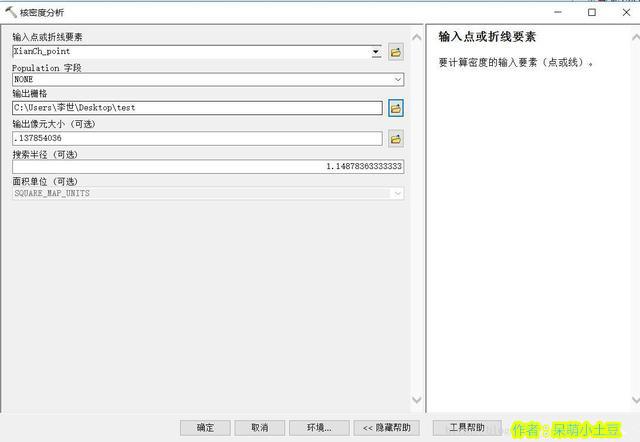
上面是核密度分析的几个参数:
搜索半径:搜索半径参数值越大,生成的密度栅格越平滑且概化程度越高。值越小,生成的栅格所显示的信息越详细
像元大小:如果专门进行设置,则是环境中的值。如果未设置环境,单元大小为输出空间参考中输出范围的宽度或高度较小值除以 250。
population:如果不使用任何项目或特殊值,则选择 None,这样每一要素就只计数一次。如果输入了某字段,则每个点计算该字段次数。
如果输入要素包含 Z,则可以使用 形状。
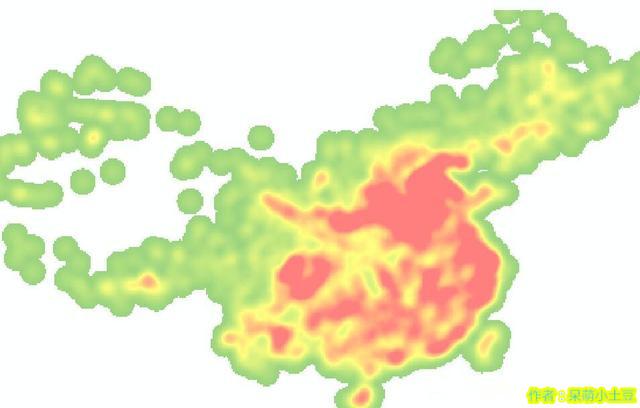
上面是分别对同一组数据进行核密度和点密度分析的结果,很明显,核密度分析的结果较为平滑。
2.核密度分析的应用
2.1 基于点的核密度
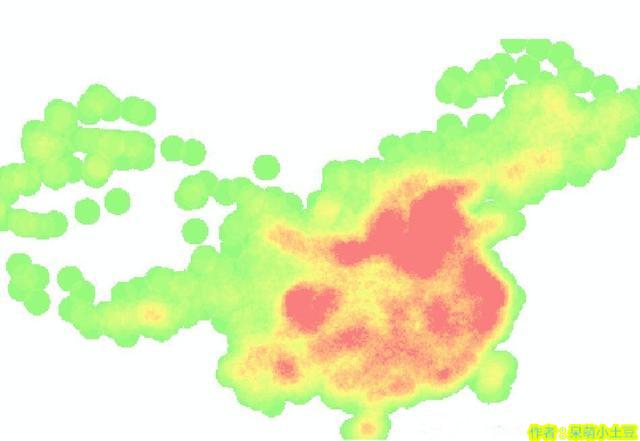
以邯郸市餐厅表为例,我们要分析出邯郸市最优的餐饮商业区。
我们首先想到的是,物美价廉。也就是说,价格要低,评分要高,人气要旺。
加入我们直接在表中进行字段计算,那么得到的最终评分是对应某个餐厅的,并不能发现商业区是如何。
所以我们先基于评分,评论数,分布,价格等分别进行核密度分析。得到基于不同属性的热力图。
单独的某一属性并不能代表什么。我们需要使用栅格计算器进行加权计算,将不同热力图赋予不同权重(比如价格权重要是负值,而评分则是越高越好),得到最终的热力图。
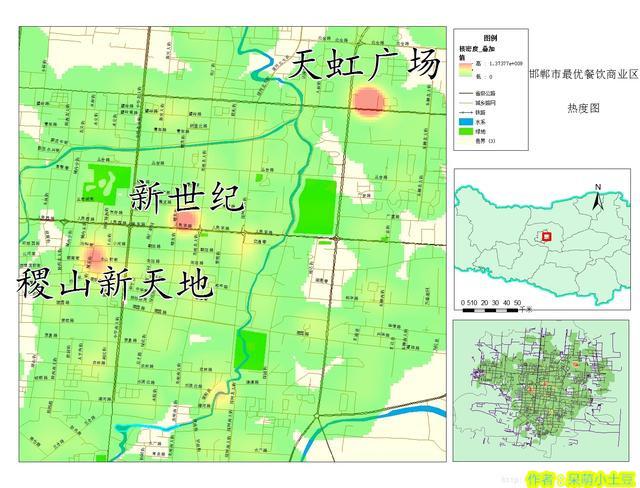
最终图很明显,三个商业区(天虹广场,新世纪,稽山新天地)的得分很明显高于其他商业区。
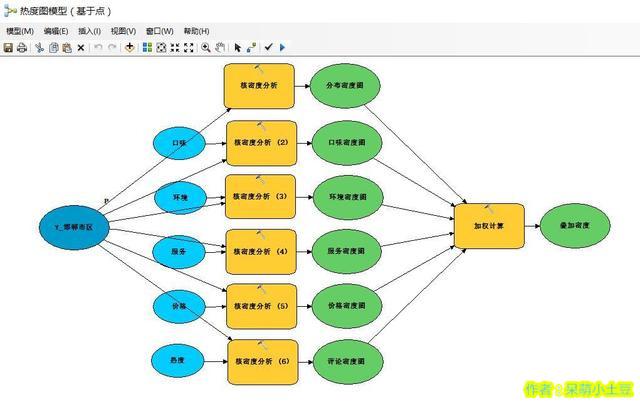
下面是模型:
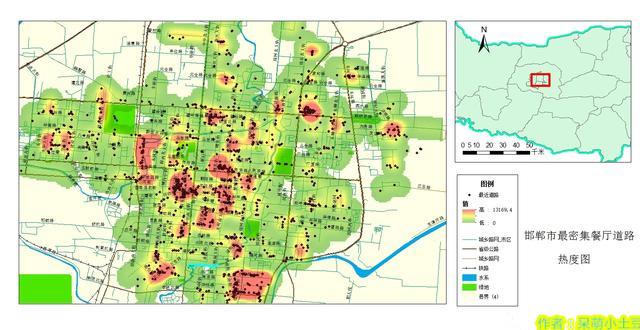
2.2基于线的核密度
再来分析一下邯郸市餐饮最繁华的路段,这里只选择数量作为评分标准。

我们要找到每条道路分布的餐厅数量,直接以道路为目标表进行空间链接是做不到的。我们先理清一下思路。
以餐厅为目标表,道路为源表进行空间链接,我们就能找到每个餐厅最近的道路。(注意,在进行空间链接的时候必须要设定坐标系,最好是投影坐标系)
再在连接后的表中,以道路分组进行汇总,就能得到每条道路对应的餐厅个数。
基于每条道路上的餐厅个数,我们就能出一副专题图:
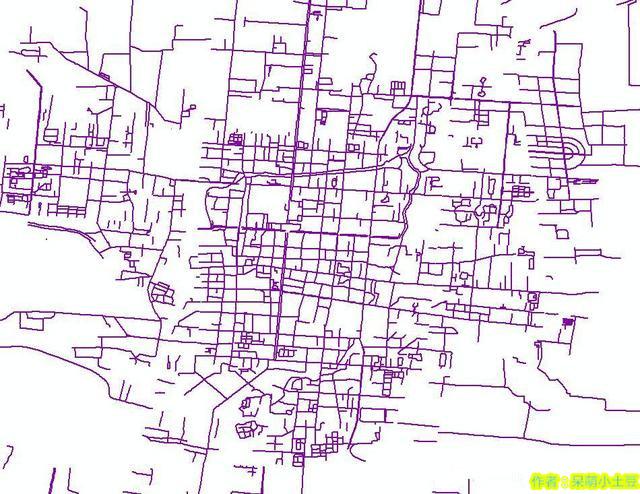
然后我们以每条道路的餐厅数为Population字段,进行核密度分析,就能得到最终的道路热力图。
下面是构建的模型:

.jpg